商务合作联系微信:telegram: @tianmeiapp
站长邮箱:[email protected]
译者:王婉婷、张菊燕
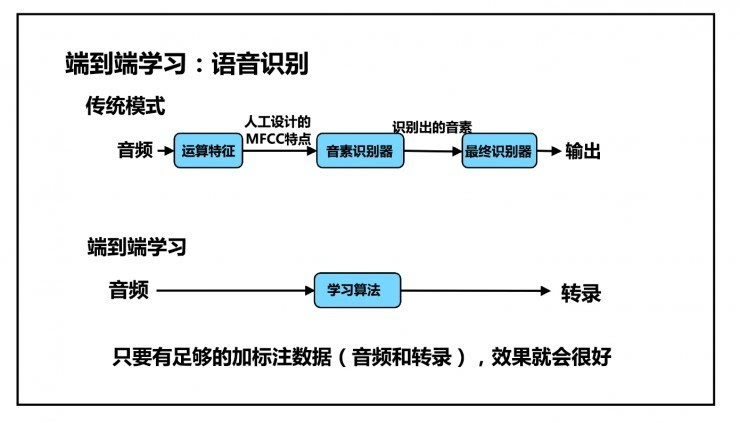
前言:在大多数情况下都能超越人类的单一语音识别系统 ( ) 的未来即将到来。
论文作者:Dario ,,Eric ,Carl Case,Jared ,Bryan ,Chen,Mike ,Adam ,Greg ,Erich Elsen,Jesse Engel,Linxi Fan,,Tony Han,Awni ,Billy Jun,,Libby Lin, , Ng , Ozair,Ryan, , ,David, ,Yi Wang, Wang,Chong Wang,Bo Xiao,Dani ,Jun Zhan, Zhu
百度研究院今日公布了硅谷人工智能实验室 (SVAIL) 的研究成果。结果包括仅使用一种学习算法即可准确识别英语和中文的能力。深度学习系统验证了一种端到端的语音识别方法,而不是使用神经网络来识别手部。
硅谷人工智能实验室去年推出的深度语音系统刚刚开始专注于提高餐厅、汽车和公共交通等嘈杂环境中英语语言识别的准确性。
去年,硅谷人工智能实验室提高了 在英语中的表现,并对其进行了普通话翻译训练。国语版在很多场景下都达到了很高的准确率,可以在移动端网页搜索等现实应用中大规模部署。
博士。百度首席科学家 Ng 评论道:“SVAIL 证明我们的端到端深度学习方法可用于识别差异很大的语言。我们方法的关键是我们使用高性能计算技术,这导致与去年同期相比,速度提高了 7 倍。由于这种效率,以前需要数周才能完成的实验现在需要数天时间。这使得迭代速度更快。”
首席科学家 Bill Dally 博士评论深度语音的高性能计算框架:“利用批处理技术 () 在 GPU 上部署动态神经网络 (DNN) 进行语音识别,然后实现这样的语音识别效率,这让我印象深刻。当在 16 个 GPU 的集群上训练 RNN(循环神经网络)时,深度语音也实现了显着的吞吐量( )。”
在网站上的一篇论文中,SVAIL 还报告说,深度语音正在学习处理世界各地的各种口语问题。目前,这种处理对于移动设备上流行的语音系统来说是一个挑战。深度学习在包括印度英语在内的许多中英文口音以及英语不是第一语言的欧洲国家的英语口音方面取得了快速进展。
“去年,当我看到深度演讲处于起步阶段时,我就感受到了它的潜力,”卡内基梅隆大学工程学院助理研究教授 Ian Lane 博士说,“今天,在相对较短的时间内, Deep 自 2000 年以来取得了重大进展。使用端到端系统,它不仅可以处理英语,还可以处理普通话,并且正在走向产品化。我对百度的批处理调度过程(Batch)及其能力的看法——影响深度神经网络在云 GPU 上的部署方式——非常有趣。”
更具体的结果在网站上的相应论文——《Deep 2: End-to-End in and .》中有介绍。


新致远精选部分论文翻译:
总结
我们展示了一种端到端的深度学习方法,可用于识别英语或汉语普通话(两种截然不同的语言)的语音。因为这种方法用神经网络代替了所有手工制作的管道,这种端到端的学习使我们能够在各种不同的情况下处理语音,包括嘈杂的环境、口音和不同的语言。我们方法的重点是应用 HPC 技术,它为我们的原始系统带来了 7 倍的加速。基于如此高的效率,以前需要数周才能完成的实验现在可以在几天内完成。这使我们能够更快地迭代,识别更好的结构和算法。因此,在某些情况下,我们的系统在标准数据集台上所做的识别与人工转录相当。最后,通过在数据中心应用一种称为“GPU 批量调度”(使用 GPU)的方法,我们表明我们的系统在在线环境中部署成本并不高(服务时延迟仍然很低。
简介
数十年的手领域知识注入当前最先进的自动语音识别 (ASR) 管道。一个简单但有效的替代解决方案是端到端训练此类 ASR 模型,使用深度学习并用单个模型替换大部分组件。我们展示了我们的第二代语音系统,它充分展示了端到端学习方法的主要优势。 Deep 2 ASR 管道在多个基准测试中接近或超过了 人类工作者的准确度,它以多种语言运行,几乎没有修改,并且可以部署到生产设置 () 下。因此,它代表了在单个 ASR 系统解决人类处理的所有语音识别上下文的领域中迈出的重要一步。由于我们的系统是建立在端到端深度学习(end-to-end deep)系统上的,我们能够采用一系列深度学习技术:捕获大型训练集、训练大型模型以进行高性能计算和方法论探索神经网络框架的空间。我们表明,通过这些技术,我们将以前的端到端系统的错误率降低了 43%,并且还可以高精度地识别普通话。
语音识别的一个挑战是语音和语音的广泛可变性。因此,现代 ASR 管道由许多组件组成,例如复杂的特征提取、声学模型、语言和发音模型、说话人适应算法等。构建和调试这些单独的组件使得开发新的语音识别模块 ( ) 变得困难,尤其是对于新语言。事实上,许多部件在不同的环境或语言中都不会产生良好的结果,并且通常需要支持多个特定于应用程序的系统以提高可接受的精度。这种情况与人类语音识别不同:人们在童年时期就具有学习任何语言的先天能力,使用通用技能来学习语言。在学会读写之后,大多数人可以翻译语音并抵抗外部环境、说话者口音和噪音的可变性,而无需在翻译任务中进行特殊训练。为了满足语音识别用户的期望,我们认为单个引擎必须学会拥有类似的能力;只需进行微小更改即可处理大多数应用程序,并从头开始学习一门新语言而无需进行重大更改。我们的端到端系统非常接近,使我们能够在两种不同语言(普通话和英语)的某些测试中接近或超过人类工人的表现。
由于 Deep 2 (DS2)是一个端到端的学习系统,我们能够通过关注三个重要部分来实现性能提升:
1、模型(模型)
2、大标签训练集()
3、计算尺度(刻度)
这种方法还在计算机视觉和自然语言等其他应用领域取得了重大进展。本文详细介绍了我们在语音识别的三个部分中所做的贡献,包括对模型框架的广泛调查、数据的影响以及识别性能方面的模型大小。特别是,我们描述了一些使用神经网络的实验,这些实验通过使用 CTC(链式时间分类算法)损失函数进行训练来预测音频中的语音翻译。我们认为应用于 RNN 的网络由多个层组成:循环连接 ( )、卷积过滤 ( )、非线性层 ( ) 以及批归一化的特殊情况的效果 ( )。我们发现该网络不仅产生了比以前的工作更好的预测,而且还发现了可以在生产环境中部署而不会显着降低准确性的循环模型示例。
不仅限于寻找更好的模型框架,深度学习系统还极大地受益于大型训练集。我们详细描述了我们的数据捕获管道(数据),这导致我们创建了比以往更大的数据集来训练语音识别系统。我们的英语识别系统接受了 11,940 小时的语音训练,而我们的普通话则接受了 9,400 小时的语音训练。我们在训练期间使用数据合成来进一步强化数据。
对大量数据进行训练通常需要使用大型模型。事实上,我们的模型比以前的模型有更多的参数。以这种规模训练一个模型需要几十个,在单核 GPU 上执行需要 3 到 6 周。这使得模型探索成为一个耗时的过程,因此我们使用 8 或 16 个 GPU 构建高度优化的训练系统来训练模型。与之前使用参数服务器和异步更新的大型训练方法相比,我们使用同步 SGD,在测试新想法时更容易调试,并且在相同程度的数据并行度下也能够更快地收敛。为了使整个系统更高效,我们描述了单核 GPU 上的优化和多核 GPU 上可扩展性的改进。我们采用通常用于高性能计算 (HPC) 的优化技术来提高可扩展性。这些优化包括在 GPU 上快速实现 CTC 损失函数,以及自定义内存分配器。我们还使用精心集成的计算节点的自定义实现和全能加速预 GPU 通信。在 16 核 GPU 上训练时,系统整体保持在 /.这意味着在每个 GPU 上,大约 50% 的理论峰值性能。这种可扩展性和效率将训练时间缩短至 3 到 5 天,这使我们能够更快地迭代模型和数据集。
我们在几个公开可用的测试数据集上对我们的系统进行了基准测试,并将结果与我们之前的端到端系统进行了比较。我们的目标是最终实现人类水平的性能,不仅是在特定的基准测试(这些基础测试可以通过调整其数据集进行调试),而且还包括反映不同场景的一系列基准测试。为此,我们还测量了人类工人的表现以进行比较。我们发现我们的系统在一些共同研究的基准上优于人类英语语音识别在线翻译,并在更难的例子上缩小了差距。除了公共基准之外,我们还在反映真实产品场景的内部数据集上展示了普通话系统的性能。
深度学习系统可能难以大规模部署。评估每个用户口音的大型神经网络在计算上是昂贵的,并且一些网络框架比其他网络框架更容易部署。通过模型探索,我们发现了一个高度准确、可部署的网络框架,我们还将在本文中详细介绍。我们还采用了一种适用于 GPU 硬件的批处理方案,称为批处理调度 (Batch),因此我们的普通话引擎在生产服务器上得到了高效的实时实现。我们的方法实现了 67 毫秒的 98% 计算延迟,而服务器同时加载了 10 个音频流。
论文简介如下。我们首先对深度学习、端到端语音识别的相关工作进行调查,然后在第 2 节可扩展性中,第 3 节描述对框架和模型的算法改进,第 4 节解释如何有效地计算它们。我们在第五节讨论了训练集和进一步加强训练集所需的步骤。第六节介绍了 DS2 系统在英语和普通话中的分析结果。最后(第 7 节)描述了将 DS2 部署到实际用户所需的步骤。
英文识别结果
最好的 DS2 模型有 11 层,包括 3 个 2D 卷积层、7 个双向循环 (nt) 层和 1 个使用的全连接(完全)输出层。第 1 层将结果输出到 (),时间步长为 3。与此相反,DS1 模型在其 5 层结构中有 1 个双向循环层,第 1 层将结果输出到 unary(),时间步长2。我们报告了 DS2 模型和 DS1 模型的一些测试集结果,我们没有在任何测试的语音上下文中调整或调整这两个模型。语言模型解码参数在保持集上只设置一次。
为了了解我们的系统在实际情况下的表现,我们将大部分结果与人类转录的文本作为基准进行比较,因为语音识别是人类特别擅长的听觉感知和语言理解问题我们通过雇佣土耳其人来手动转录所有测试语音,从而获得了人类水平的表现水平。每个音频片段的长度约为 5 秒,由 2 人转录。我们从 2 个转录本中选择更好的一个用于最终的 WER(单词错误率,Rate)计算。转录员可以无限次地收听每个音频片段。这些员工中的大多数都在美国,每个录音平均需要 27 秒才能收听。将手动输入的结果与现有的真实记录 ( ) 进行比较以获得 WER 值。尽管现有的真实记录确实存在一些标记错误( ),但这基本上不超过1%。这表明,人类水平的转录和真实录音之间的差异可以帮助我们了解人类水平的表现 ( )。
语音朗读
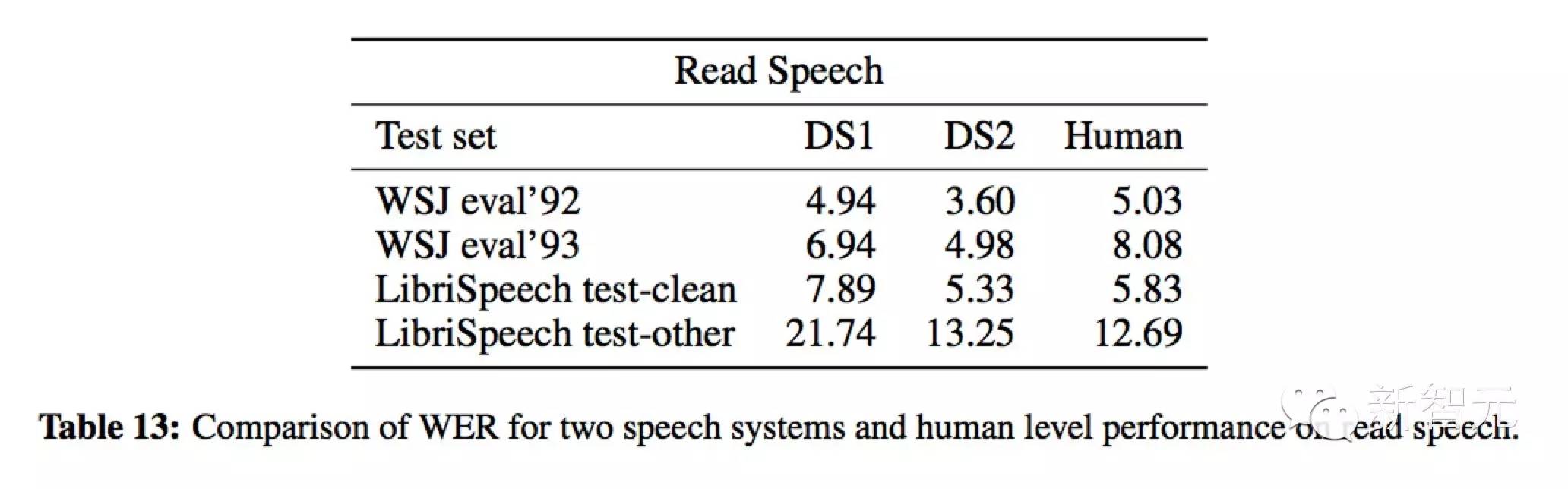
表 13 显示,在 4 个测试集上,DS2 识别系统在 3 个测试集上的表现优于人类,在第 4 个测试集上与人类相差不远。基于这样的结果,我们怀疑一般的识别系统在没有特定领域适应的情况下,在纯语音阅读方面几乎没有改进空间。
重音
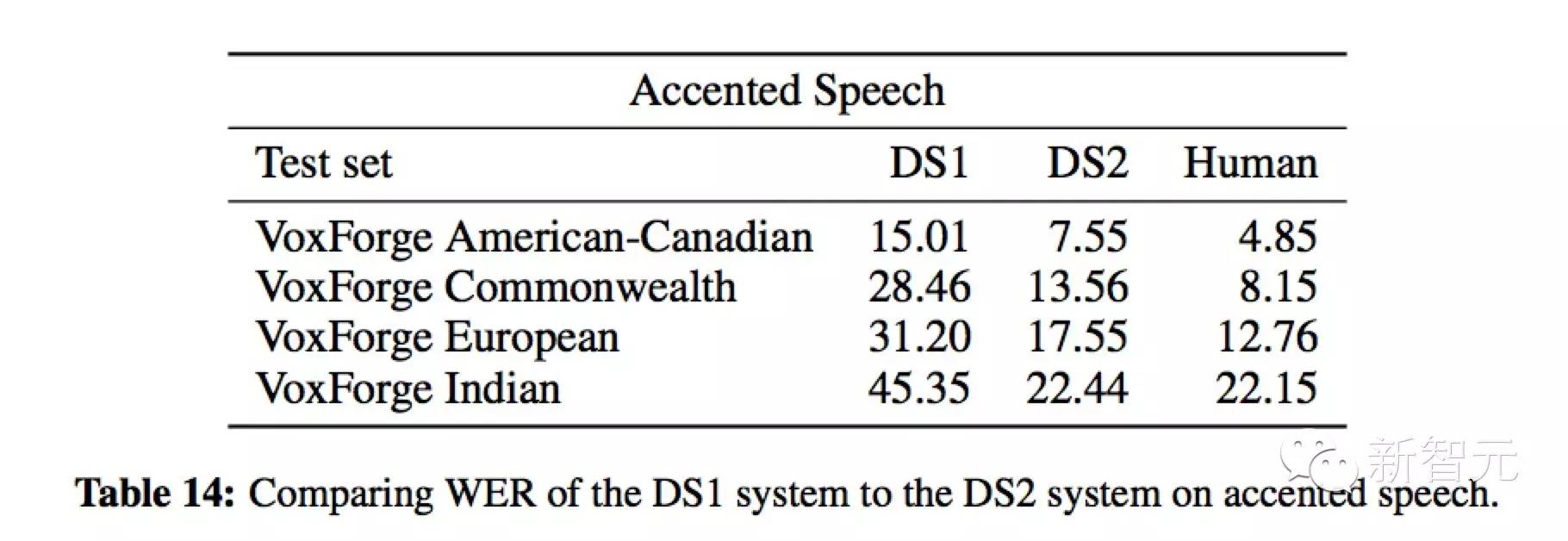
表 14 显示,当我们将更多带口音的语音材料纳入训练数据并应用有效训练这些数据的结构时,识别系统在所有口音方面都会得到改善。然而,人类水平的性能仍然比 DS2 识别系统强得多——除了印度口音。
噪音环境中的语音嘈杂
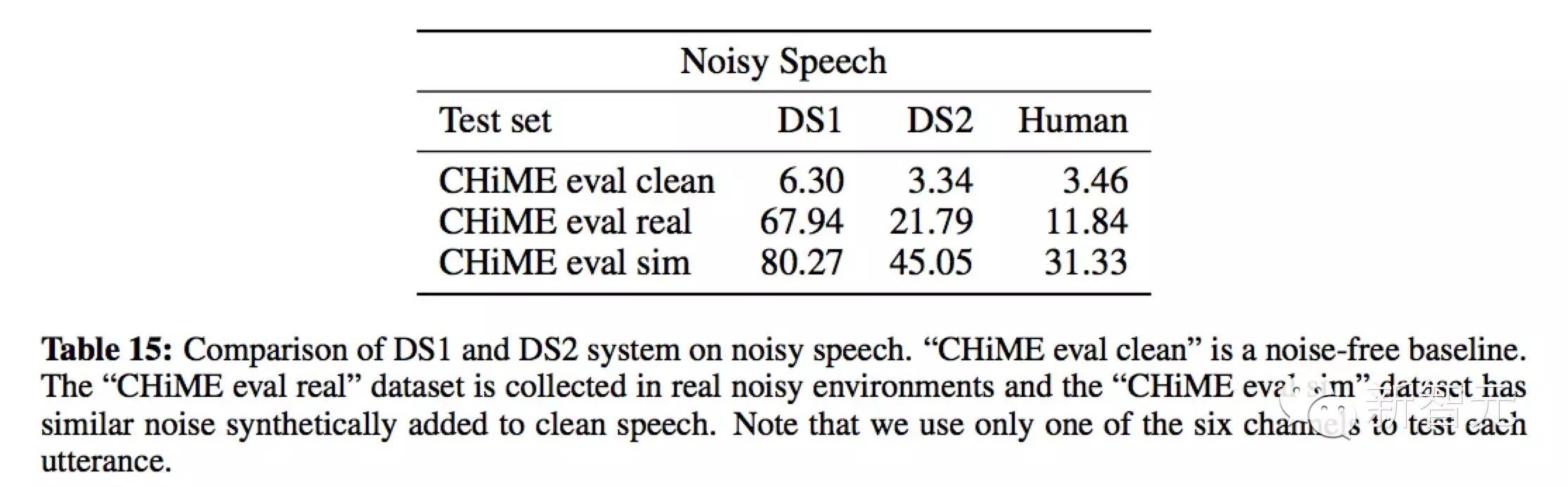
表 15 显示 DS2 相比 DS1 有很大的提升英语语音识别在线翻译,但 DS2 在嘈杂环境中的语音识别能力仍然不如人类。与在纯语音上叠加噪声相比,DS2在真实噪声环境下的语音与人的差距更大。
中文识别结果

在表 16 中,我们比较了几种不同的模型结构,这些模型结构基于 2000 个短语音段 (该开发集还用于调整解码参数。我们发现,具有 2D 不变卷积 (2D-) 的最深模型和最浅的 RNN 模型将性能提高了 48%,这与我们在英语识别系统上看到的趋势一致——多层双向递归可以大大提高语音识别性能。
我们还发现,我们一流的普通话识别系统在转录简短语音方面的表现甚至优于典型的大陆人。为了以人类为基准,我们进行了一项测试,我们随机选择了 100 个简短的演讲,并要求 5 个人类一起转录它们。这组人的错误率为 4%,而语音识别系统的错误率为 3.7%。我们还比较了单个人类转录器和识别系统,在 250 个随机选择的语音片段上,识别系统的表现比人类好得多:语音识别系统的错误率为 5.7%,而人类达到9.7%。
总结
随着数据和计算量的增加,端到端深度学习是提高语音识别系统性能的一个令人兴奋的机会。事实上,我们的结果表明,与其前身 () 相比,在更多数据和更大模型的帮助下,显着缩小了与人类的转录差距。不仅如此,而且由于这种方法非常通用,我们证明它可以快速适应新的语言。为两种截然不同的语言——英语和普通话——创建高性能语音识别器并不需要这些语言的专业知识。最后,我们还展示了这种方法可以通过在 GPU 服务器上批处理用户请求来有效地部署,为实施端到端深度学习技术以服务用户奠定了基础。
为了获得这些结果,我们探索了不同的神经网络架构并发现了一些有效的技巧:通过用 Batch 增强数值优化( () 被评估,并且 () 在双向和单向模型中执行。我们正在使用受高性能计算启发而优化的训练模型,这使我们能够在短短几天内训练全新的、真实大小的(全规模)数据集)模型。
总体而言,我们相信我们的结果证实并证明了端到端深度学习在多个场景中对语音识别的价值。在某些情况下,我们的系统还没有达到与人类相媲美的地步,但与人类的差距正在迅速缩小,这在很大程度上是因为深度学习技术对应用程序不敏感(-)。我们相信这些技术将继续扩展,因此我们得出的结论是,在大多数情况下都可以超越人类的单一语音识别系统 ( ) 的未来即将到来。
下载论文全文
请回复1210在新知源微信订阅号(28页)下载论文全文(28页)

干货下载1.【华创证券】机械设备:机器人趋势2.【东吴证券】大国崛起:中国智能制造值得中长期布局< @3.【广发证券】清扫机器人:昔日的王燮堂、千言,飞入寻常百姓家
如何下载?关注新知源微信订阅号(),回复“12月下载”即可获取。

商务合作联系微信:telegram: @tianmeiapp
站长邮箱:[email protected]
原文链接:硅谷人工智能实验室(SVAIL):端对端深度学习方法,转载请注明来源!