1. 文件上传
我们知道我们可以模拟提交一些数据。 如果有些网站需要我们上传文件,我们也可以使用它来上传。 实现非常简单。 示例如下:
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
print(r.text)
在上一节中,我们下载并保存了一个名为 .ico 的文件。 这次我们就以它为例来模拟一下文件上传的过程。 需要注意的是,.ico 文件需要与当前脚本位于同一目录下。 如果还有其他文件,当然可以用其他文件上传,改个名字就可以了。
运行结果如下:
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAAAAA...="
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "6665",
"Content-Type": "multipart/form-data; boundary=809f80b1a2974132b133ade1a8e8e058",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.10.0"
},
"json": null,
"origin": "60.207.237.16",
"url": "http://httpbin.org/post"
}
省略上面的部分,这个网站会返回一个文件,里面包含files字段,而且形式为空推特注册收不到手机验证码,这证明文件上传部分会有一个单独的files字段来标识。
2.
之前我们用的是,写法比较复杂。 但有了它,获取和设置可以一步完成。
我们先通过一个例子来体验一下获取过程:
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key, value in r.cookies.items():
print(key + '=' + value)
运行结果如下:
'''
]>
BDORZ=27315
'''
首先我们调用属性并成功获取。 我们可以发现它是一个类型。 然后我们使用items()方法将其转换为元组列表,遍历并输出每一个元组的名称和值,实现遍历分析。
当然我们也可以直接用它来维护登录状态。
比如我们以知乎为例,直接用它来维护登录状态。
首先登录知乎并复制,如下图:
您可以将其替换为您自己的,将其放入其中并发送。 示例如下:
import requests
headers = {
'Cookie': 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://www.zhihu.com', headers=headers)
print(r.text)
发现结果包括登录后的结果,如下图:

运行结果证明登录成功。
当然也可以通过参数来设置,但是这样的话需要构造对象并进行划分,比较麻烦,但是效果是一样的。 示例如下:
import requests
cookies = 'q_c1=31653b264a074fc9a57816d1ea93ed8b|1474273938000|1474273938000; d_c0="AGDAs254kAqPTr6NW1U3XTLFzKhMPQ6H_nc=|1474273938"; __utmv=51854390.100-1|2=registration_date=20130902=1^3=entry_date=20130902=1;a_t="2.0AACAfbwdAAAXAAAAso0QWAAAgH28HQAAAGDAs254kAoXAAAAYQJVTQ4FCVgA360us8BAklzLYNEHUd6kmHtRQX5a6hiZxKCynnycerLQ3gIkoJLOCQ==";z_c0=Mi4wQUFDQWZid2RBQUFBWU1DemJuaVFDaGNBQUFCaEFsVk5EZ1VKV0FEZnJTNnp3RUNTWE10ZzBRZFIzcVNZZTFGQmZn|1474887858|64b4d4234a21de774c42c837fe0b672fdb5763b0'
jar = requests.cookies.RequestsCookieJar()
headers = {
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36'
}
for cookie in cookies.split(';'):
key, value = cookie.split('=', 1)
jar.set(key, value)
r = requests.get('http://www.zhihu.com', cookies=jar, headers=headers)
print(r.text)
上面我们首先创建了一个新的对象,然后使用 split() 方法分割复制的对象,使用 set() 方法设置每个对象的 key 和 value,然后调用 get() 方法并将其传递给参数。 当然由于知乎本身的限制,参数不能缺失,但是原参数中不需要设置字段。
经过测试,发现可以正常登录知乎。
3. 会话维护
中,如果我们直接使用get()或者post()等方法,确实可以模拟网页请求。 但这其实就相当于不同的会话,也就是不同的,也就是说你用两个浏览器打开不同的页面。
想象一个场景,我们的第一个请求使用 post() 方法登录网站。 登录成功后第二次我们想要获取您的个人信息时推特注册收不到手机验证码,您再次使用get()方法请求个人信息页面。 。 其实这相当于打开了两个浏览器,是两个完全不相关的会话。 个人信息能否顺利获取? 当然不是。
有的朋友可能会说了,那两个请求中设置相同的设置不就可以了吗? 是的,但这样做似乎仍然很乏味。 我们有一个更简单的解决方案。
事实上,解决这个问题的主要方法是保持同一个会话,这相当于打开一个新的浏览器选项卡,而不是打开一个新的浏览器。 但我不想每次都设置,那该怎么办呢? 这时候,就有了一个新的武器对象。
使用它,我们可以轻松维护一个会话,而且无需担心出现问题,它会自动为我们处理。
我们用一个例子来感受一下:
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
r = requests.get('http://httpbin.org/cookies')
print(r.text)
例子中我们请求了一个测试URL: ,要请求这个URL我们可以设置一个名字叫,内容是,然后请求这个URL来获取当前的。
这样能成功获取到设置吗? 试一试。
运行结果如下:
{
"cookies": {}
}
并不真地。 让我们再试一次:
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
r = s.get('http://httpbin.org/cookies')
print(r.text)
看一下运行结果:
{
"cookies": {
"number": "123456789"
}
}
获取成功! 您现在能体会到相同对话和不同对话之间的区别了吗?
因此,我们可以模拟同一个会话而不必担心。 通常用于模拟登录成功后再进行下一步。
它在日常生活中应用广泛,可以用来模拟在浏览器中打开同一站点的不同页面。 后面会有专门的章节来解释这部分内容。
4.SSL证书验证
提供证书验证功能。 当发送HTTP请求时,它会检查SSL证书。 我们可以通过这个参数来控制是否检查这个证书。 其实如果不加的话,默认是True,会自动验证。
前面我们提到12306证书实际上并没有被官方认可,会导致证书验证错误。 现在我们访问时,可以看到一个证书问题页面,如下图:
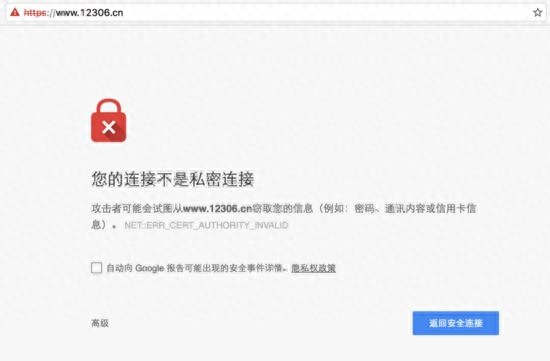
出现错误页面
现在我们来测试一下:
import requests
response = requests.get('https://www.12306.cn')
print(response.status_code)
运行结果如下:
..: ("坏:错误([('SSL ', '', ' ')],)",)
提示错误,称为证书验证错误。 所以如果我们请求一个HTTPS站点,但是页面出现证书验证错误,就会报这样的错误。 那么如何避免这个错误呢? 很简单,把这个参数设置为False即可。
更改为以下代码:
import requests
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
这样就会打印一个表示请求成功的状态码。
/usr/local/lib/python3.6/site-packages/urllib3/connectionpool.py:852: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) 200
但是我发现报了一个警告,建议我们给它分配一个证书。
我们可以通过设置忽略警告方法来阻止这个警告:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
或者通过在日志中捕获警告来忽略警告:
import logging
import requests
logging.captureWarnings(True)
response = requests.get('https://www.12306.cn', verify=False)
print(response.status_code)
当然我们也可以指定一个本地证书作为客户端证书,它可以是单个文件(包含密钥和证书),也可以是包含两个文件路径的元组。
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)
当然,上面的代码只是一个例子。 我们需要有 crt 和密钥文件并指定它们的路径。 注意,本地私有证书的密钥必须是解密状态的密钥,不支持加密状态的密钥。
5. 代理设置
对于某些网站,测试时多次请求后即可正常获取内容。 但一旦开始大规模爬取,对于大规模、频繁的请求,网站可能会直接登录验证、验证代码,甚至直接屏蔽IP。
所以为了防止这种情况发生,我们需要设置一个代理来解决这个问题,就需要用到这个参数。
可以这样设置:
import requests
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
requests.get('https://www.taobao.com', proxies=proxies)
当然,可能无法直接运行该实例,因为代理可能无效。 请使用您自己的有效代理尝试。
国外苹果ID/美日韩台、新加坡、香港等——韩国区已过年龄认证17+ 19+ 的苹果id游戏应用下载——独享美区ID小火箭账号-——正版苹果商店礼品卡、软件兑换码点击购买

谷歌锁区号/谷歌邮箱老号-购买商城-谷歌PLAY锁区账号/美区、日区,韩区,台区,新加坡谷歌账号等谷歌账号购买、代注册谷歌账号,代申诉解封———>点击购买
原文链接:模拟文件上传的高级用法,代理设置,设置等等,转载请注明来源!